Table Of Content

So our analysis respects that blocks are present, but does not attempt any statistical analyses on them. Because this is an orthogonal design, the sums of squares doesn’t change regardless of which order we add the factors, but if we remove one or two observations, they would. In each of the partitions within each of the five blocks, one of the four varieties of rice would be planted. In this experiment, the height of the plant and the number of tillers per plant were measured six weeks after transplanting. Both of these measurements are indicators of how vigorous the growth is. The taller the plant and the greater number of tillers, the healthier the plant is, which should lead to a higher rice yield.
Designer Jobs By Location
Blocking factors and nuisance factors provide the mechanism for explaining and controlling variation among the experimental units from sources that are not of interest to you and therefore are part of the error or noise aspect of the analysis. The mathematical subject of block designs originated in the statistical framework of design of experiments. These designs were especially useful in applications of the technique of analysis of variance (ANOVA). In statistics, the concept of a block design may be extended to non-binary block designs, in which blocks may contain multiple copies of an element (see blocking (statistics)). There, a design in which each element occurs the same total number of times is called equireplicate, which implies a regular design only when the design is also binary.
Designer gender statistics
In the example above, the cell phone use treatment (yes vs. no) cannot interact with driving experience. This means the effect of cell phone use treatment (yes vs. no) on the dependent variable, driving ability, should not be influenced by the level of driving experience (seasoned, intermediate, inexperienced). In other words, the impact of cell phone use treatment (yes vs. no) on the dependent variable should be similar regardless of the level of driving experience.
Designer gender ratio
Intercontinental Exchange Reports February 2024 Statistics - Business Wire
Intercontinental Exchange Reports February 2024 Statistics.
Posted: Tue, 05 Mar 2024 08:00:00 GMT [source]
Furthermore, as mentioned early, researchers have to decide how many blocks should there be, once you have selected the blocking variable. We want to carefully consider whether the blocks are homogeneous. In the case of driving experience as a blocking variable, are three groups sufficient? Can we reasonably believe that seasoned drivers are more similar to each other than they are to those with intermediate or little driving experience?
In other words, every combination of treatments and conditions (blocks) is tested. The next thing you need to do after you determine your blocking factors is allocate your observations into blocks. To simplify things, we will assume that you have one main blocking factor that you want to balance over.
Moreover, he knows that his plots are quite heterogeneous regarding sunshine, and therefore a systematic error could arise if sunshine does indeed facilitate corn cultivation. Suppose that skin cancer researchers want to test three different sunscreens. They coat two different sunscreens on the upper sides of the hands of a test person.
Average designer age
An ovoid in PG(3,q) is a set of q2 + 1 points, no three collinear. It can be shown that every plane (which is a hyperplane since the geometric dimension is 3) of PG(3,q) meets an ovoid O in either 1 or q + 1 points. The plane sections of size q + 1 of O are the blocks of an inversive plane of order q. A resolvable 2-design is a BIBD whose blocks can be partitioned into sets (called parallel classes), each of which forms a partition of the point set of the BIBD. The set of parallel classes is called a resolution of the design.
Designs without repeated blocks are called simple,[3] in which case the "family" of blocks is a set rather than a multiset. Interpretation of the coefficients of the corresponding models, residualanalysis, etc. is done “as usual.” The only difference is that we do not test theblock factor for statistical significance, but for efficiency. Instead of a single treatment factor, we can also have a factorial treatmentstructure within every block.
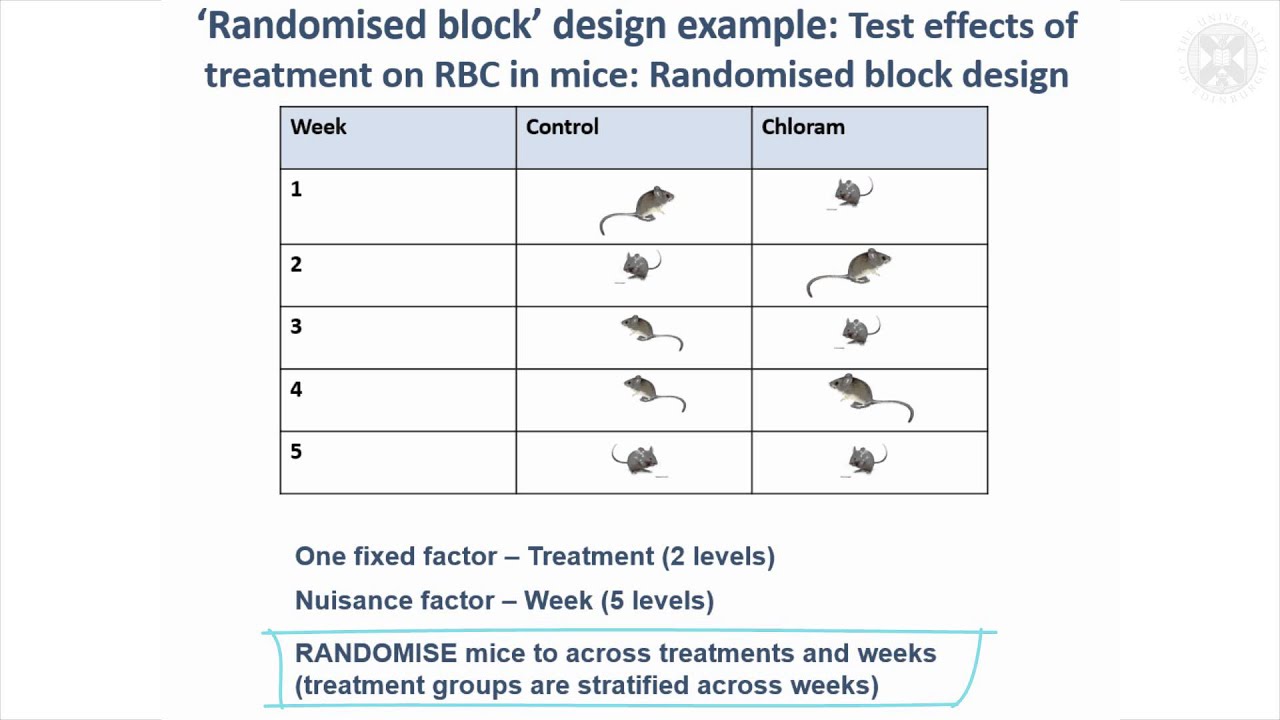
First the researchers need to identify a potential control variable that most likely has an effect on the dependent variable. Researchers will group participants who are similar on this control variable together into blocks. This control variable is called a blocking variable in the randomized block design.
Soybean yield variability per plant in subtropical climate: sample size definition and prediction models for precision ... - ScienceDirect.com
Soybean yield variability per plant in subtropical climate: sample size definition and prediction models for precision ....
Posted: Thu, 10 Mar 2022 07:08:06 GMT [source]
We already know how to deal with these variables by adding them to the model, but there are experimental designs where we must be careful because the experimental treatments are nested. To address nuisance variables, researchers can employ different methods such as blocking or randomization. Blocking involves grouping experimental units based on levels of the nuisance variable to control for its influence. Randomization helps distribute the effects of nuisance variables evenly across treatment groups. Often there are covariates in the experimental units that are known to affect the response variable and must be taken into account. Ideally an experimenter can group the experimental units into blocks where the within block variance is small, but the block to block variability is large.
Can also considered for testing additivity in 2-way analyses when there is only one observation per cell. Comparing the two ANOVA tables, we see that the MSE in RCBD has decreased considerably in comparison to the CRD. This reduction in MSE can be viewed as the partition in SSE for the CRD (61.033) into SSBlock + SSE (53.32 + 7.715, respectively). The potential reduction in SSE by blocking is offset to some degree by losing degrees of freedom for the blocks.
A Latin Square design blocks on both rows and columnssimultaneously. If we ignore the columns of a Latin Square designs, the rows form anRCBD; if we ignore the rows, the columns form an RCBD. However it would be pretty sloppy to not do the analysis correctly because our blocking variable might be something we care about. To make R do the correct analysis, we have to denote the nesting. In this case we have block-to-block errors, and then variability within blocks. To denote the nesting we use the Error() function within our formula.
So we have to be smart enough to recognize that plot and subplot are actually Variety and Fertilizer. First we have 6 blocks and we’ll replicate the exact same experiment in each block. Within a block, we’ll split it into three sections, which we’ll call plots (within the block). Ideally I wouldn’t have to do the averaging over the nested observations and we would like to not have the misleading p-values for the plots. To do this, we only have to specify the nesting of the error terms and R will figure out the appropriate degrees of freedom for the covariates. Here is Dr. Shumway stepping through this experimental design in the greenhouse.








No comments:
Post a Comment